
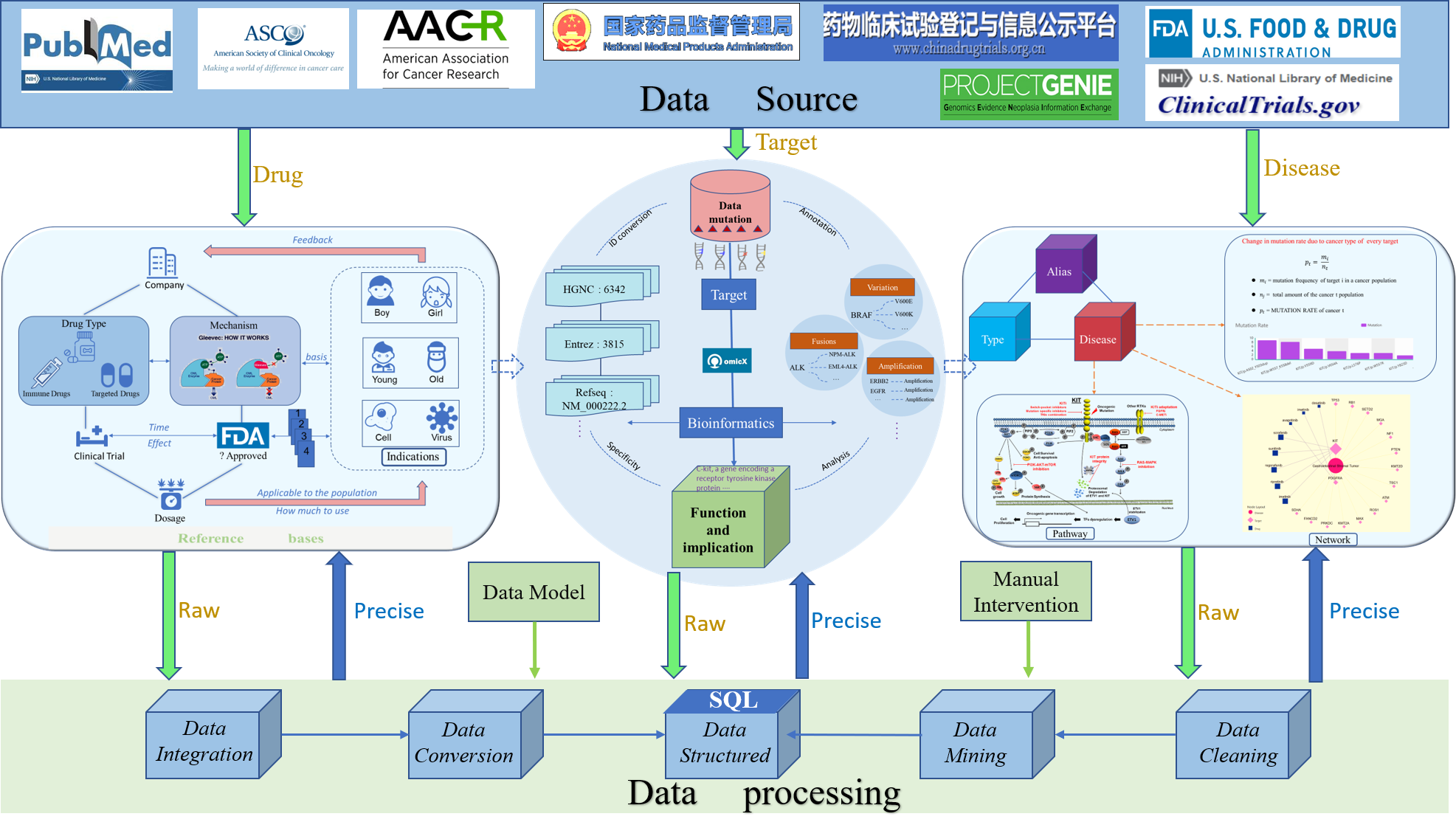
Target-disease-drug relationships were collected from multiple public resources, including Drug Approvals and Databases at Food and Drug Administration (FDA), American Society of Clinical Oncology (ASCO), National Comprehensive Cancer Network (NCCN) guidelines, OncoKB, CIViC, and scientific literatures. The drug approval information was derived from Food and Drug Administration (FDA), European Medicines Agency (EMA), or National Medical Products Administration of China (NMPA). The Clinical trials related to specific drugs and efficacy were compiled from the datasets from https://clinicaltrials.gov.
The gene or gene variants were linked to or presented with multiple external databases, such as GENECARDS, OMIM, COSMIC, ClinVar, dbSNP, KEGG, REACTOME, and NCG. The population carrier rate of gene variants was calculated using the datasets from AACR Project Genomics Evidence Neoplasia Information Exchange (GENIE) cohort and The Cancer Genome Atlas (TCGA) cohort.
The cancer type names were standardized using OncoTree ontology and the disease classification was compiled with the NCI thesaurus scheme. The cancer-specific pathways were obtained through literature review and the links to the corresponding references were provided.
All data was organized in several structured tables and managed with the MySQL database system. The data tables were indexed using self-defined internal keys to optimize data query and retrieval.
Yun-Juan Bao, Ph.D. Professor of Bioinformatics
School of Life Sciences, Hubei University
Email: yjbao@hubu.edu.cn
